-
데이터 전처리 편데이터 분석 (Data Analysis) 2023. 9. 16. 20:16SMALL
데이터 전처리는 본격적인 분석 전 매우 중요한 단계로, 데이터의 품질을 향상시키고 분석에 적합한 형태로 만드는 과정이다.
데이터 타입에 따라서, 전처리 방법이 달라지기도 하고 풀고자하는 Task에 따라서도 전처리 기법은 다를 수 있다.
먼저 데이터 전처리에 대해 설명하고, 이후 상황 별 데이터 전처리 예시들에 대해 소개한다.
1. 데이터 전처리 (Data Preprocessing) 이란?
데이터 전처리는 데이터를 정제, 변환 하고 추가하는 과정을 의미한다.
실제 데이터를 마주하면 값이 비어있거나, 비정상적인 값이 포함된 경우도 많고 정상적으로 입력은 되었지만 보편적인 수준을 넘어서 값이 비정상적으로 크거나 작은 경우도 있다. 이러한 값들을 적절하게 처리하여 분석 결과가 합리적이고 유의미할 수 있도록 만드는 과정으로 데이터 전처리는 매우 중요하다!
1-1. 데이터 정제 (Data Cleaning)
데이터 정제 과정에서는 수집된 데이터 자체를 검토한다.
- 결측값 처리 (Missing Values Handling)
- 결측값은 기입되지 않은 값을 의미하며 Missing Values, NA 등으로 표현된다.
- 결측값을 대체하는 방법은 Data imputation 으로 불리며 평균, 중앙값으로 채워넣을 수도 있고 시계열이면 spline 보간법 등 데이터 타입과 데이터 문맥에 따라 적절한 기법을 선택할 필요가 있다. 이와 같이 결측값은 적절한 대체값으로 채워넣거나 해당 레코드를 삭제하는 방법으로 처리한다.

Source: https://www.scaler.com/topics/data-science/categorical-missing-values/ - 이상값 제거 (Remove Outliers)
- 이상값은 주로 다른 데이터 포인트들과는 매우 다른 특성을 가지거나, 규칙을 벗어나는 특징을 보이는 값이다. 이상 값을 식별하고 처리하여 분석 / 모델의 영향을 줄인다.
- 이상값도 제거하는 방법을 쓸 수도 있고, 적절한 값으로 대체하는 방법 등 다양한 기법으로 처리할 수 있다.
- 만일 이상값이 포함된 상태로 모델링을 하게 된다면, 모델의 분산이 커져서 모델의 정확성을 떨어뜨리는 이슈가 발생할 가능성이 있다.
- 참고로, 이상값은 보편적인 모델 성능을 높이기 위해 제거되기도 하지만, 반대로 분석의 목적 자체가 이상값 탐지인 경우도 있다. 이때는 이상값 탐지 (Outlier Detection) 모델을 활용하게 되고 이상값 탐지모델도 단순 Box-plot 부터 isolated Forest 등 다양한 기법을 활용해 구할 수 있다.
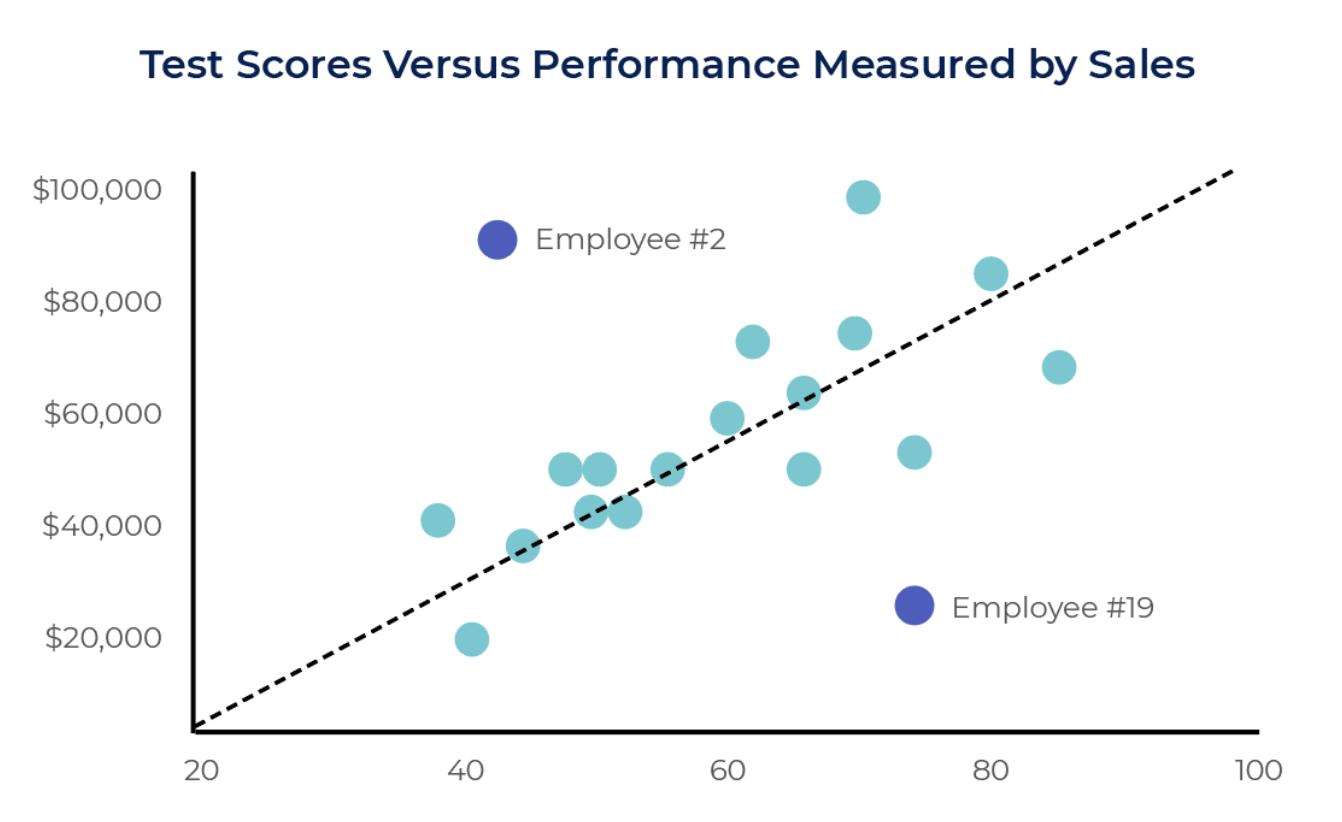
Source: https://www.criteriacorp.com/resources/glossary/outlier 1-2. 데이터 변환 (Data Transformation)
- 피쳐 스케일링 (Feature Scaling)
- 단위가 다른 변수들이 모여있을 때 데이터의 스케일을 조정한다.
- 표준화 Z-score normalization, Min-Max scaling, Robust Scaling 등 여러 기법이 있다.
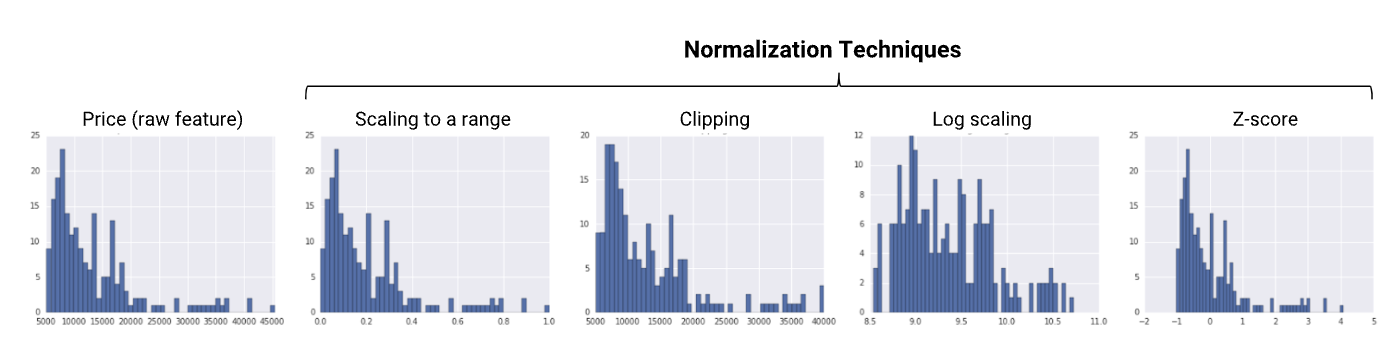
Source: https://developers.google.com/machine-learning/data-prep/transform/normalization?hl=ko *x축을 보면 차이를 확인할 수 있다.
- 피쳐 인코딩 (Feature Encoding)
- 범주형 데이터를 수치형 데이터로 변환하기 위해 라벨 인코딩, 원-핫 인코딩 등을 사용한다.
- 라벨 인코딩 (Label Encoding): 범주형 데이터를 숫자로 변환한다.
- 원-핫 인코딩 (One-Hot Encoding): 범주형 데이터를 벡터로 변환하여 각 범주에 해당하는 열을 생성한다.
데이터 예시
Major in Univ. Students # Statistics 100 Security 150 Computer Science 80 Finance 200 Label Encoding
Major in Univ. Label Encoding Statistics 1 Security 2 Computer Science 3 Finance 4 One-Hot Encoding
Statistics Security Computer Science Fiance # of Students 1 0 0 0 100 0 1 0 0 150 0 0 1 0 80 0 0 0 1 200 1-3. 피쳐 엔지니어링 (Feature Engineering)
피쳐 엔지니어링 과정에서는 기존에 존재하는 변수를 활용해서, 새로운 정보를 추가로 생성한다.
즉, 새로운 데이터를 결합하는 것이 아니고 현재 데이터를 활용해 새로운 정보를 추가한다.
보유중인 변수가 충분하지 않을때에도 활용할 수 있고, 변수에 변환을 주어서 모델 성능을 개선한다. 데이터 불균형이 큰 경우에는 샘플링 기법도 활용할 수 있다. 개인적으로 피쳐 엔지니어링 과정을 매우 좋아한다. 리소스 소모는 적으면서 창의력 싸움인 느낌?!ㅎㅎ 게다가 성능 개선에도 직접적으로 영향을 많이 주는 절차여서 결과에 어떤 변수가 필요할지 역으로 고민하는 과정에서 많은 재미를 느끼게 된다. 예를 들어, 태풍을 예측하는 모델을 만든다고 할때, 현재 가진 데이터는 강수량 변수이고 여기서 0~10mm, 10mm ~ 100mm, 100mm 초과에 따라 강수 level 범주등을 설정해 모델에 넣는다거나 어제와 오늘의 강수량 차이를 생성해 모델에 넣는 등 Task 에 맞춰 다양한 방법으로 시도가 가능하다.
2. 상황 별 데이터 전처리
데이터 분석시 발생하는 모든 케이스를 다룰 수는 없으므로 몇가지 예시들을 생각해보았다. 아래에 작성된 내용 이외에도 충분히 많은 변수들이 발생할 수 있다!
2-1. 데이터 샘플링 (Data Sampling)
- 불균형이 큰 데이터에서 Over Sampling 혹은 Under Sampling을 통해 데이터 균형을 맞춰 모델 성능을 높일 수 있다. 만일 불균형이 큰 데이터를 샘플링 없이 통째로 학습하게 된다면 많은쪽의 Class 데이터를 과하게 학습해 과적합 (Overfitting)이 발생할 수 있다.
2-2.시계열 데이터 전처리 (Time Series Data Processing)
- 시계열 데이터에 결측이 있는 경우, 시간 정보를 활용하여 결측값을 처리한다.
- 직전에 관측된 값으로 대체
- 직후에 관측된 값으로 대체
- 일정 Time Interval을 두고 해당 Interval의 평균으로 대체
- 선형 보간 (Linear interpolation) 등
2-3. 텍스트 데이터 처리 (Text Data Processing)
- 텍스트 데이터의 경우 분석에 적절하게 변환하기 위해 몇가지 절차들이 필요하다.
- 토큰화 (Tokenization): 문장이나 문서를 단어나 문장 단위로 나눈다.
- 불용어 제거 (Stopword Removal): 자주 나오지만 의미 없는 단어를 제거한다.
- 텍스트 데이터는 토크나이징 방법도 다양하고, 불용어 사전도 용도에 맞게 활용해야한다.
- 예를 들어 Oh! Hello Kitty, I love it. 라는 문장이 있다고 가정하자. (뜬금 ㅋㅋㅋ)
- 해당 문장에서 Hello Kitty 를 묶을 것인지 나눌것인지도 설정해야한다. 단순 space 기준으로 토크나이징 한다면 묶여야 하는 'Hello Kitty'와 같은 용어들이 분리되는 불상사가 발생한다. 또한, 불용어에 만일 Hello 를 포함시켜 두었는데, Hello Kitty 가 1개의 단어가 아니라 Hello 와 Kitty 로 나뉜다면 Hello 가 사라져서 Kitty 만 남게 될 것 이다. 이와 같이, 텍스트 데이터는 전처리에서 면밀하게 검토하고 분석으로 넘어갈 필요가 있다.
데이터를 완벽하게 처리하는 것은 불가능하므로, 적절한 전처리 방법을 선택하여 최대한 데이터의 품질을 향상시키는 것이 중요하다. 다음편부터는 본격적으로 데이터 분석 기법에 대해 다루려고 하는데, 먼저 텍스트 데이터 분석부터 시작해볼 예정이다! 아자아자!
반응형LIST'데이터 분석 (Data Analysis)' 카테고리의 다른 글
텍스트마이닝 (1) Bag-Of-Words (BoW) (0) 2023.10.15 텍스트 마이닝 개요 (Text Mining) (0) 2023.09.29 기술통계 분석과 시각화 (Visualization) - 기초편 (0) 2023.09.09 데이터 형식과 타입 (1) 2023.09.03 데이터 분석 목표과 절차 (8) 2023.08.27 - 결측값 처리 (Missing Values Handling)